shell-Startup-Files
1. 相关阅读 2. 主流shell 3. shell实例类型 4. Shell启动文件的必要元素 4.1 路径: 命令路径, 4.2 提示符 5. 主流shell的配置文件 6. 默认的bash 6.1 手册 6.2 bash启动文件 6.3 提示符 7. 友好的fish 7.1 简介 7.2 查看帮助文档 7.3 fish的配置 8. zsh
1. 相关阅读
https://www.cnblogs.com/sztom/p/11349159.html
shell脚本
https://szosoft.blogspot.com/2019/07/console-terminal-tty-shell-kernel.html
https://www.cnblogs.com/sztom/p/11247883.html
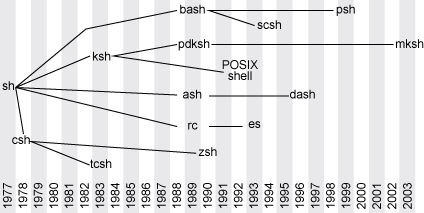
Console-terminal-tty-shell-kernel
Shell在计算机系统中的位置
http://hyperpolyglot.org/unix-shells
常用shell语法对照(Unix Shells: Bash, Fish, Ksh, Tcsh, Zsh)
https://en.wikipedia.org/wiki/Comparison_of_command_shells
https://opensource.com/business/16/3/top-linux-shells
Linux的前5个开源命令shell
https://www.ibm.com/developerworks/cn/aix/library/au-spunix_fish/index.html
Friendly Interactive Shell(fish)对于 UNIX 新手和专家都很适合
https://wiki.archlinux.org/index.php/Command-line_shell
https://wiki.archlinux.org/index.php/Command-line_shell#POSIX_compliant
https://wiki.archlinux.org/index.php/Command-line_shell#Alternative_shells
https://en.wikipedia.org/wiki/Unix_shell
https://en.wikipedia.org/wiki/Unix_shell#Configuration_files
https://wiki.gentoo.org/wiki/Shell
https://wiki.gentoo.org/wiki/Shell#Available_software
https://en.wikibooks.org/wiki/Bash_Shell_Scripting
https://developer.ibm.com/tutorials/l-linux-shells/
2. 主流shell
| Name | Description | POSIX | License | user |
| bash (默认) |
The Bourne Again Shell, is the default shell on Gentoo. It is used by Portage, Gentoo's default package manager. | 符合 compliant | GPLv3 | 54% |
| fish (友好) |
The Friendly Interactive Shell. (2005) | Alternative 替代 | GPLv2… | 12% |
| zsh (极客) |
An advanced shell that is the chosen interactive shell for many users. | 符合 compliant | MIT, GPL | 23% |
| tcsh | an enhanced version of the Berkeley C Shell (csh). | Alternative 替代 | BSD | 3% |
| ksh | The Original Korn Shell, 1993 revision (ksh93). | 符合 compliant | Eclipse Public | 3% |
| Other | 5% |


https://developer.ibm.com/developer/tutorials/l-linux-shells/images/figure1.gif
3. shell实例类型
| 大类 | 小类 | 系统配置文件 | 用户配置文件 |
| 交互式 | 登录shell (初始shell) | /etc/profile | .bash_profile; .bash_login; .profile … |
| 交互式 | 非登录shell | /etc/bash.bashrc | .bashrc |
| 非交互式 | 运行shell脚本的shell等 | 通常不读取启动文件 |
4. Shell启动文件的必要元素
路径,提示符,别名alias,权限掩码(077;022)4.1 路径: 命令路径,
/usr/local/bin/usr/bin
/bin
这个顺序可以确保/usr/local中的特定变体覆盖默认程序。
大多数Linux发行版中,几乎所有软件包都会被安装到/usr/bin中。也有少数情况(游戏: /usr/games; 图形应用还有另外的地方)
可以将一些分散程序的符号链接放到/usr/local/bin中。
若对系统工具感兴趣(traceroute,ping,lsmod...),可以为路径加上sbin目录。
/usr/local/sbin
/usr/sbin
/sbin
帮助手册的路径: 建议不要修改。
传统的帮助手册路径来自环境变量MANPATH. /etc/manpath.config
4.2 提示符
PS1='[\u@\h \w]\n\A \!-\#\$ '5. 主流shell的配置文件
| files | bash | sh | ksh | zsh | tcsh |
| /etc/.login | login | ||||
| /etc/csh.login | login | ||||
| ~/.login | login | ||||
| ~/.logout | login | ||||
| /etc/csh.cshrc | yes | ||||
| ~/.tcshrc ; ~/.cshrc | yes[a] | ||||
| ~/etc/ksh.kshrc | int. | ||||
| /etc/sh.shrc | int.[b] | ||||
| $ENV (typically ~/.kshrc) | int.[e] | int.[c][d] | int. | ||
| ~/.bashrc | int.+n/login | ||||
| ~/.bash_profile | login[g] | ||||
| ~/.bash_login | login[g] | ||||
| ~/.bash_logout | login | ||||
| ~/.profile | login[g] | login | login | login[f] | |
| /etc/profile | login | login | login | login[f] | |
| /etc/zshenv | yes | ||||
| /etc/zprofile | login | ||||
| /etc/zlogin | login | ||||
| /etc/zlogout | login | ||||
| /etc/zshrc | int. | ||||
| ~/.zshenv | yes | ||||
| ~/.zprofile | login | ||||
| ~/.zlogin | login | ||||
| ~/.zshrc | int. |
| n/login | 表示如果shell不是登录shell,则读取文件。 |
| login | 表示如果shell是登录shell,则读取文件。 |
| int. | 表示如果shell是交互式的,则读取文件。 |
| yes | 表示shell在启动时始终读取文件。 |
| " " | 空白表示shell根本不读取文件。 |
| [a] | 仅在找不到~/.tcshrc时 |
| [b] | 仅限Bourne Shell的较新版本 |
| [c] | 适用于支持"用户可移植性实用程序"选项的系统; 变量的值必须是绝对路径,如果用户的真实有效用户ID或真实有效的组ID不同,则忽略它。 |
| [d] | $ENV是在Bourne Shell中的较新版本$HOME/.shrc |
| [e] | 与 sh相同的行为,但仅在调用为 sh(bash 2+)或者自bash 4.2时,如果在POSIX兼容模式中显式调用(使用选项 --posix或 -o posix). |
| [f] | a,b仅在sh/ksh兼容模式下(当调用为bash,sh,ksh时) |
| [g] | 实际上是b,c,~/ .bash_profile的第一个可读,~/ .bash_login和~/ .profile ; 并且只有~/ .profile如果被调用为sh或者,至少在Bash 4.2中,如果在POSIX兼容模式中显式调用(带有选项--posix或-o posix) |
6. 默认的bash
Bash主页是 http://www.gnu.org/software/bash/https://wiki.archlinux.org/index.php/Bash
https://wiki.archlinux.org/index.php/Bash#Configuration_files
https://wiki.gentoo.org/wiki/Bash
6.1 手册
https://www.gnu.org/software/bash/manual/bash.htmlfile:///usr/share/doc/bash/bashref.html
6.2 bash启动文件
https://www.gnu.org/software/bash/manual/bash.html#Bash-Startup-Files| 文件 | 描述 | 登录shell | 交互, 非登录shell |
| /etc/profile | 来源在应用程序设置/etc/profile.d/*.sh和/etc/bash.bashrc。 | Yes | No |
| ~/.bash_profile | 用户,之后/etc/profile。如果这个文件不存在,~/.bash_login并~/.profile按照此顺序检查。骨架文件/etc/skel/.bash_profile也来源~/.bashrc。 | Yes | No |
| ~/.bash_logout | 退出登录shell后。 | Yes | No |
| /etc/bash.bashrc | 取决于-DSYS_BASHRC="/etc/bash.bashrc"编译标志。来源/usr/share/bash-completion/bash_completion。 | No | Yes |
| ~/.bashrc | 每用户,之后/etc/bash.bashrc。 | No | Yes |
https://zhuanlan.zhihu.com/p/33833752
如何列出所有的 Bash Shell 内置命令
6.3 提示符
PS1='[\u@\h \w]\n\A \!-\#\$ 'PS1='\e[0;36m\][\u@\h \w]\e[0m\] \e[0;32m\]\n\A \!-\#\$\e[0m\] '
PS1='\e[0;36m\][\u@\h \w] \e[0;32m\]\n\A \!-\#\$\e[0m\] '
Code Color
\e[0;30m\] Black
\e[0;31m\] Red
\e[0;32m\] Green
\e[0;33m\] Yellow
\e[0;34m\] Blue
\e[0;35m\] Magenta 品红
\e[0;36m\] Cyan 青色
\e[0;37m\] White
\e[0m\] Reset to standard colors 重置为标准色
7. 友好的fish
7.1 简介
https://en.wikipedia.org/wiki/Friendly_interactive_shellhttps://zh.wikipedia.org/wiki/Fish
fish的设计目标是以易于发现,记忆和使用的方式为用户提供丰富的强大功能。
它的语法既不来自Bourne shell(ksh,bash,zsh)也不是C shell(csh,tcsh)。
与以前的shell(默认情况下禁用某些功能以节省系统资源)不同,fish默认启用所有功能。
https://wiki.archlinux.org/index.php/Fish
https://wiki.archlinux.org/index.php/Fish_(简体中文)
fish被有意设计成不完全与POSIX兼容。
fish的作者们认为POSIX中存在一些缺陷和矛盾,并通过fish简化的或不同的语法解决这些问题。
因此,即使简单的POSIX兼容的脚本也可能需要较多的修改,甚至完全重写,才能在fish中运行。
https://wiki.archlinux.org/index.php/Fish#Setting_fish_as_interactive_shell_only
只把fish设为交互式shell
https://wiki.gentoo.org/wiki/Fish
fish是OS X,Linux和其他家族的智能且用户友好的命令行shell。
fish包含语法突出显示,自动提示类型和精美的选项卡完成等功能,无需配置。
Fish不是POSIX 1003.1兼容的shell。它不读取/etc/profile,/etc/profile.env或/etc/profile.d/*目录。
建议不要将fish设置为默认登录shell.
这里有其中一位鱼类开发者和Arch wiki建议的技巧。这使得fish shell能够继承bash环境(写入并应该由bash shell 执行)
详见: https://wiki.gentoo.org/wiki/Fish#.bashrc_safety_net
https://github.com/fish-shell/fish-shell
7.2 查看帮助文档
$ helpfile:///usr/share/doc/fish/index.html#docs
与其他shell不同,这里直接打开web页面文档,更方便查看,还能使用网页翻译。与下方官网页面相同。
https://fishshell.com/docs/current/index.html
官网的教学及常见问题
https://fishshell.com/docs/current/tutorial.html
https://fishshell.com/docs/current/faq.html
7.3 fish的配置
$ fish_configWeb config started at 'file:///home/toma/.cache/fish/web_config-S2EKS6.html'. Hit enter to stop.
不需要编写脚本,不需要手动修改配置文件,使用 fish_config 命令打开网页即可。
比如: http://localhost:8000/6d9de3bf1bf313e974c9738471da505c/#/colors
- colors 配色模式 (我选择了省电的黑色背景,彩色文字模式)
- prompt 提示符号 (我选择了完整路径显示加时间,加换行模式)
- functions 功能
- variables 变量
- history 历史 (这里可以看到所有已经使用过的历史命令,可以手动删除不需要的命令)
- bindings 绑定
- abbreviations 缩写
8. zsh
这个可以吧shell玩的很酷炫,有非常多的插件可以选择。也要话时间适应研究,这里就直接跳过了。
网络上有非常多的相关文章可共参考。

{kind=link}